生成式AI环境搭建
RKLLM 是 Rockchip 面向大语言模型(LLM)推出的一整套软件栈,目标是把 HuggingFace、PyTorch、ONNX 等格式的 千亿级参数大模型 快速、低比特、低延迟地部署到 RK3576 / RK3588 等 NPU 上。 它由三大组件构成:RKLLM-Toolkit(PC 端工具链)+ RKLLM Runtime(板端 C/C++ API)+ RKNPU Kernel Driver(内核驱动)。
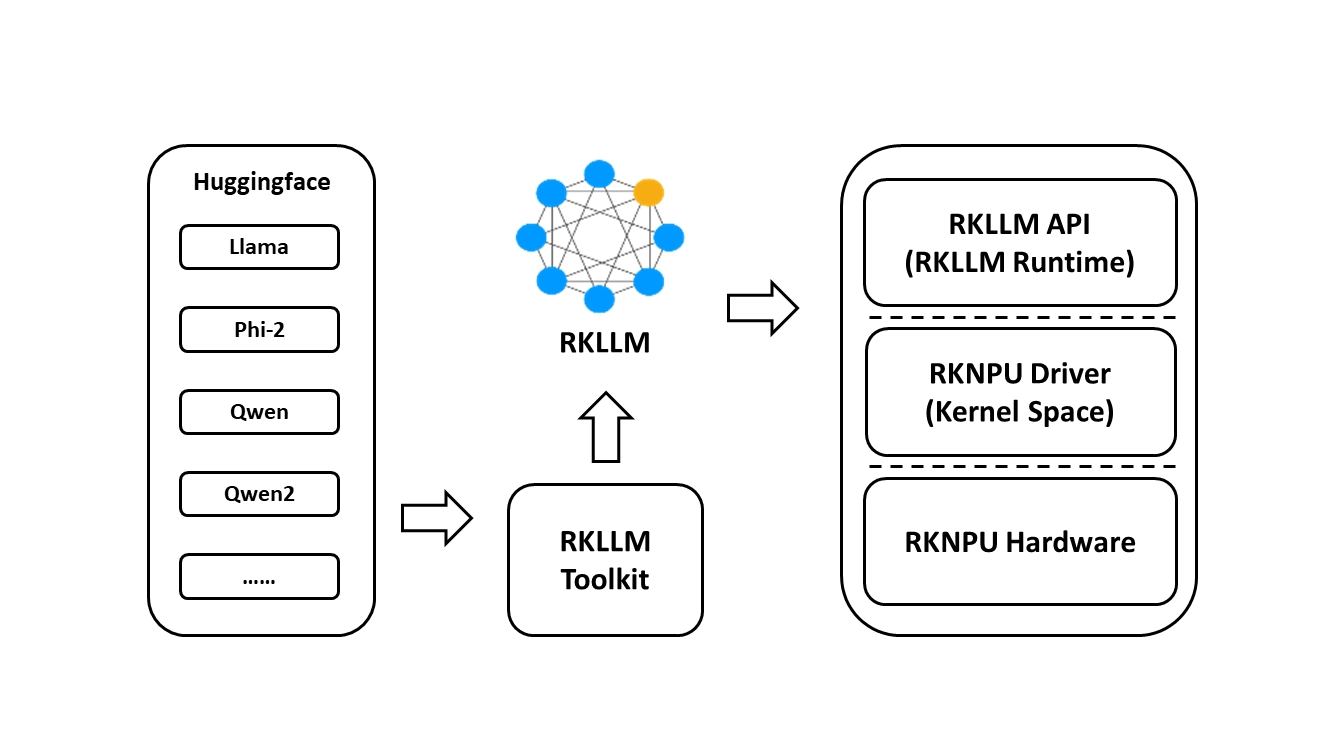
RKLLM-Toolkit(PC 端模型转换 & 量化工具链)
| 功能 | 说明 |
|---|---|
| 输入格式 | HuggingFace .bin / .safetensors、PyTorch .pt、ONNX、GGML |
| 输出格式 | .rkllm 单一文件(含权重、图结构、量化表、token-vocab) |
| 量化策略 | 支持 INT8、INT6、INT4、INT2、FP16、FP32 混合精度; |
| 内存优化 | KV-Cache 分配、权重分页、显存/内存复用分析 |
| 典型命令 | python -m rkllm_toolkit convert --model llama2-7b-hf --quant int4 --output llama2-7b-int4.rkllm |
| 运行环境 | x86_64 / Apple Silicon / WSL,无需硬件 |
RKLLM Runtime(板端 C/C++ 推理接口)
| 模块 | 作用 |
|---|---|
| librkllmrt.so | 板端动态库,提供 C API |
| 核心接口 | rkllm_init() / rkllm_run() / rkllm_destroy() |
| 示例 demo | examples/llm_inference 可直接运行 |
| 内存占用 | 7B 模型 INT4 量化后 ≈ 3.5 GB RAM(含 KV-Cache) |
| 吞吐 | RK3588 上 7B-INT4 ≈ 4~6 token/s(batch=1,室温) |
| 并发 | 支持多实例/多线程,支持流式生成 & 断句 |
1.RKLLM-Toolkit工具安装
由于RKLLM-Toolkit工具没有ARM64版本,只提供x86版本,所以只提供X86 + NVIDIA GPU PC的安装教程!
如果x86 Linux PC无NVIDIA GPU安装可能报错!!!
1.安装Anaconda,访问此链接:Anaconda
wget -c https://repo.anaconda.com/archive/Anaconda3-2025.06-1-Linux-x86_64.sh
执行安装程序
bash Anaconda3-2025.06-1-Linux-x86_64.sh
按步骤安装即可,这里不再演示。
安装完成后激活环境
source ~/.bashrc
2.创建conda环境
conda create -n rkllm python=3.11 -y
3.进入rkllm conda 环境
conda activate rkllm
4.使用git获取rkllm源码
git clone -b release-v1.2.1 https://github.com/airockchip/rknn-llm.git
5.安装 RKLLM-Toolkit
pip3 install rknn-llm/rkllm-toolkit/rkllm_toolkit-1.2.1-cp311-cp311-linux_x86_64.whl
6.验证安装
python3
>>>from rkllm.api import RKLLM
若执行无报错,即为安装成功。
2.板端测试
板端已经默认安装了NPU驱动可通过以下命令:
#执行命令
sudo cat /sys/kernel/debug/rknpu/version
#输出内容
RKNPU driver: v0.9.8
1.使用git获取rkllm源码
git clone -b release-v1.2.1 https://github.com/airockchip/rknn-llm.git