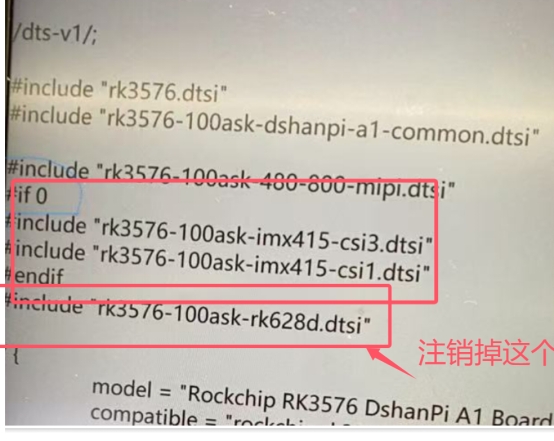
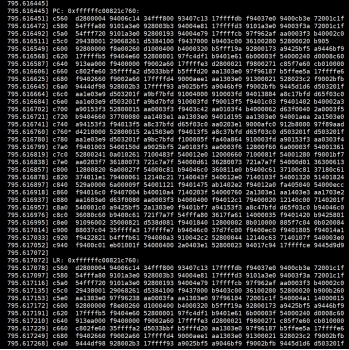
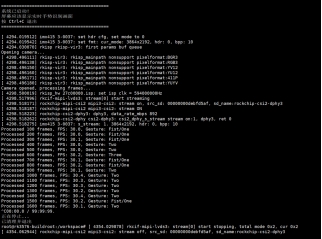
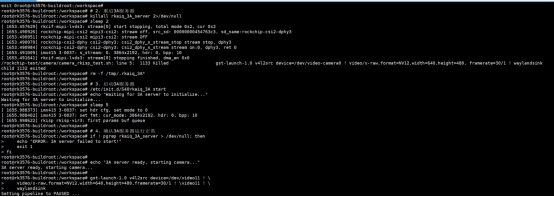
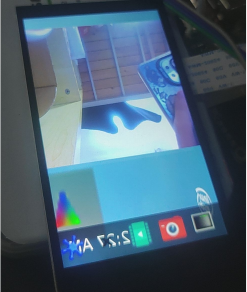
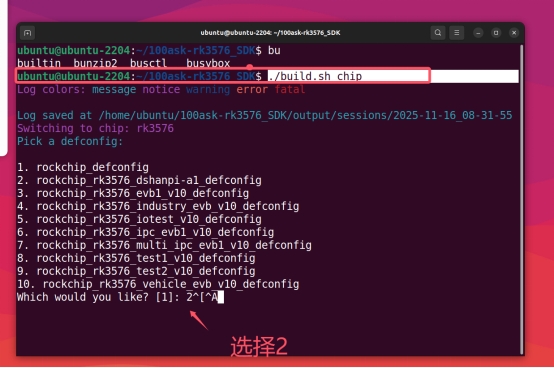
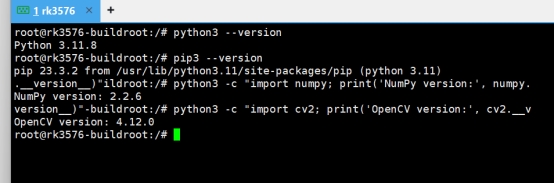
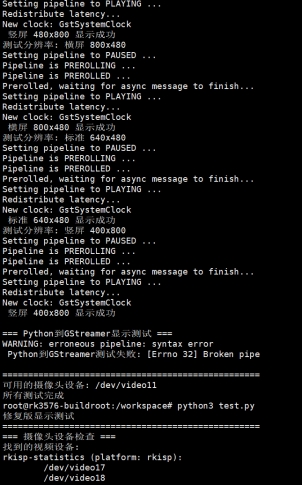
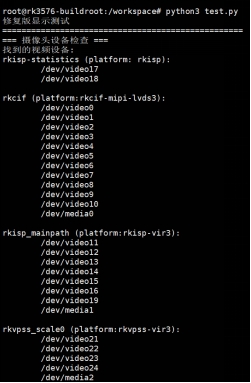
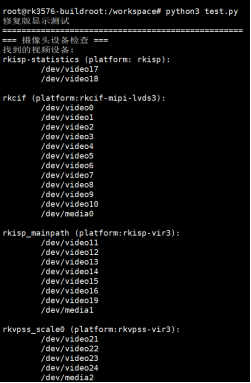
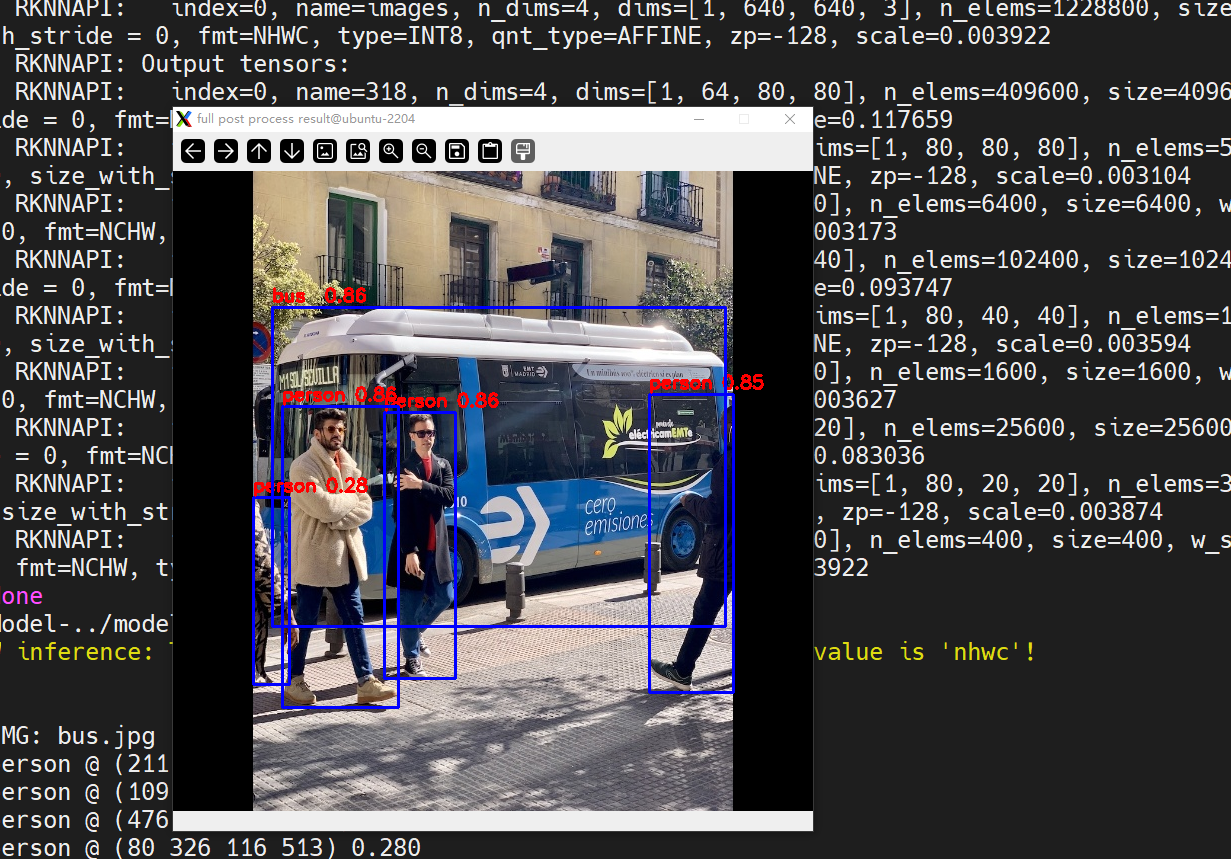
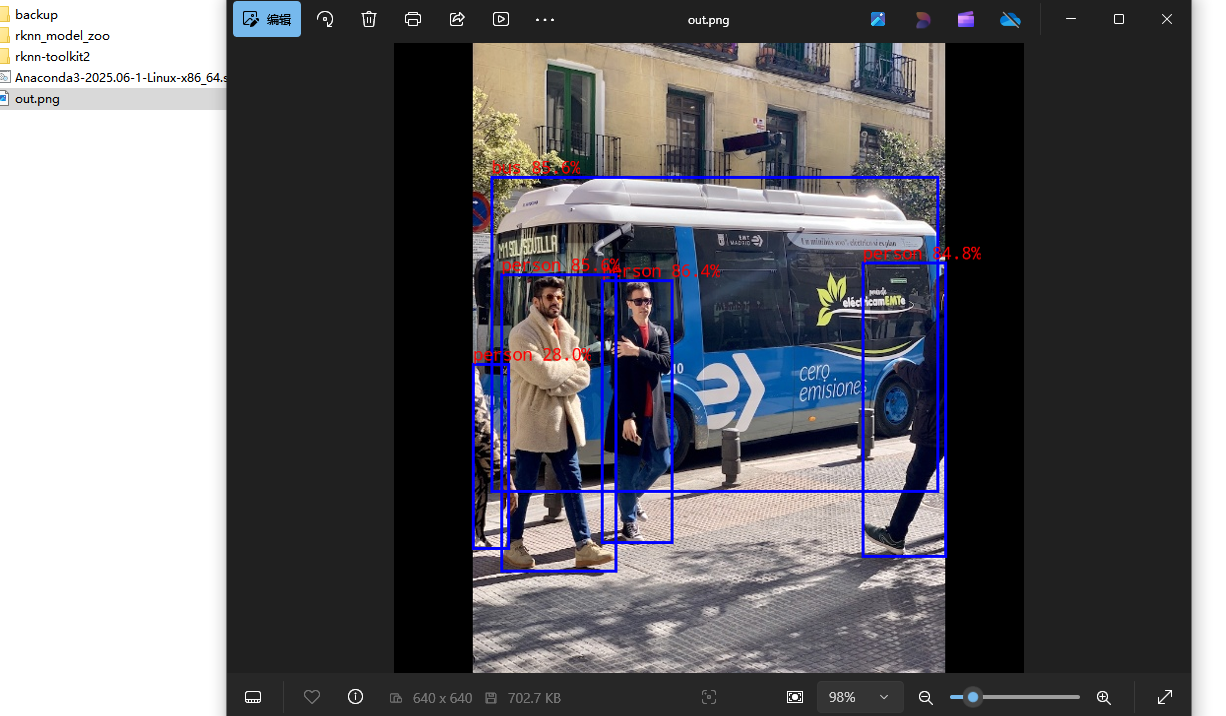
cd /npu_yolo_test
cat > yolo_npu_display.sh << 'EOF'
#!/bin/bash
echo "=========================================="
echo "YOLOv5 NPU Real-time Detection - RK3576"
echo "=========================================="
echo ""
# 重启3A服务器(摄像头自动曝光/白平衡/自动对焦)
echo "Restarting 3A server..."
killall rkaiq_3A_server 2>/dev/null
sleep 2
rm -f /tmp/.rkaiq_3A* 2>/dev/null
/etc/init.d/S40rkaiq_3A start >/dev/null 2>&1
sleep 3
# 创建FIFO管道
FIFO_PATH="/tmp/yolo_fifo"
rm -f $FIFO_PATH
mkfifo $FIFO_PATH
echo "Starting display pipeline..."
gst-launch-1.0 -q filesrc location=$FIFO_PATH ! jpegparse ! jpegdec ! videoconvert ! videoscale ! video/x-raw,width=1280,height=720 ! waylandsink fullscreen=true sync=false &
GST_PID=$!
sleep 2
echo "Starting YOLOv5 NPU detection..."
python3 - <<'PYTHON_CODE' &
import cv2
import numpy as np
import time
from rknnlite.api import RKNNLite
from collections import deque
RKNN_MODEL = '/npu_yolo_test/yolov5s-640-640.rknn'
CAMERA_ID = 11
IMG_SIZE = 640
OBJ_THRESH = 0.25
NMS_THRESH = 0.45
FIFO_PATH = '/tmp/yolo_fifo'
CLASSES = ("person", "bicycle", "car", "motorbike", "aeroplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "sofa",
"pottedplant", "bed", "diningtable", "toilet", "tvmonitor", "laptop", "mouse", "remote", "keyboard",
"cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase",
"scissors", "teddy bear", "hair drier", "toothbrush")
def xywh2xyxy(x):
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = np.expand_dims(input[..., 4], axis=-1)
box_class_probs = input[..., 5:]
box_xy = input[..., :2]*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(input[..., 2:4]*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
boxes = boxes.reshape(-1, 4)
box_confidences = box_confidences.reshape(-1)
box_class_probs = box_class_probs.reshape(-1, box_class_probs.shape[-1])
_box_pos = np.where(box_confidences >= OBJ_THRESH)
boxes = boxes[_box_pos]
box_confidences = box_confidences[_box_pos]
box_class_probs = box_class_probs[_box_pos]
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score >= OBJ_THRESH)
boxes = boxes[_class_pos]
classes = classes[_class_pos]
scores = (class_max_score * box_confidences)[_class_pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
x, y = boxes[:, 0], boxes[:, 1]
w, h = boxes[:, 2] - boxes[:, 0], boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
return np.array(keep)
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
if len(boxes) == 0:
return None, None, None
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b, c, s = boxes[inds], classes[inds], scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses:
return None, None, None
return np.concatenate(nboxes), np.concatenate(nclasses), np.concatenate(nscores)
class YOLODetector:
def __init__(self):
self.fps_queue = deque(maxlen=30)
self.last_time = time.time()
self.fps = 0.0
def calc_fps(self):
t = time.time()
if t - self.last_time > 0:
self.fps_queue.append(1.0 / (t - self.last_time))
self.fps = sum(self.fps_queue) / len(self.fps_queue)
self.last_time = t
def draw_detections(self, frame, boxes, scores, classes, scale_x, scale_y):
for box, score, cl in zip(boxes, scores, classes):
x1 = int(box[0] * scale_x)
y1 = int(box[1] * scale_y)
x2 = int(box[2] * scale_x)
y2 = int(box[3] * scale_y)
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
label = f'{CLASSES[cl]} {score:.2f}'
cv2.putText(frame, label, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
def run(self):
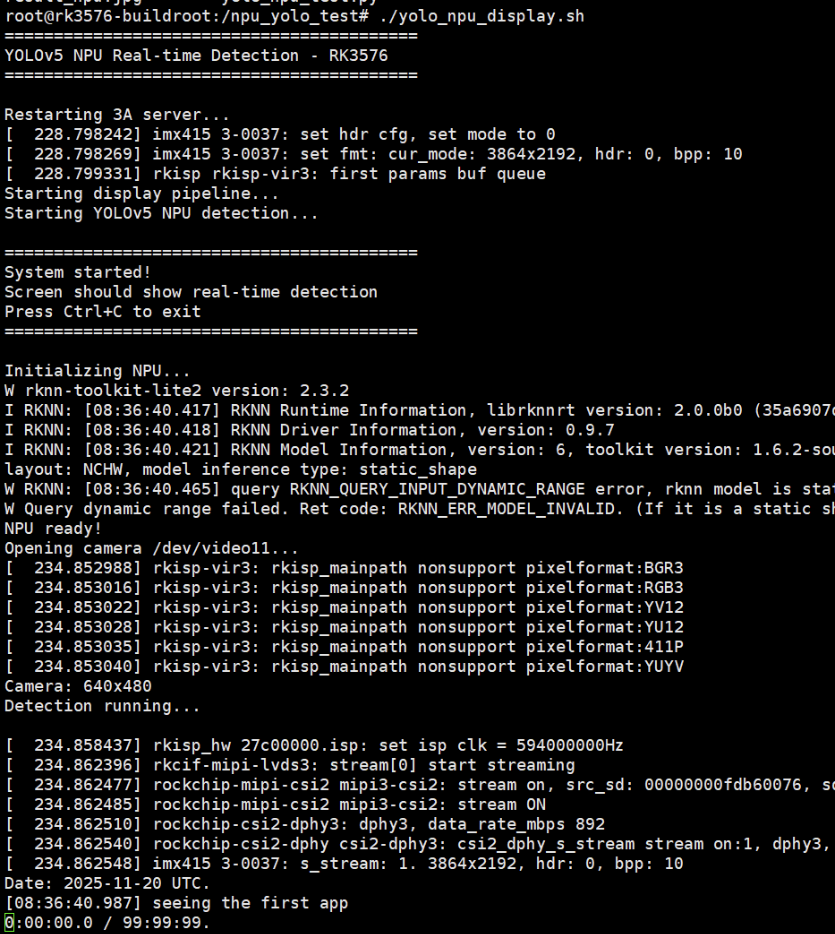
print("Initializing NPU...")
rknn_lite = RKNNLite()
rknn_lite.load_rknn(RKNN_MODEL)
rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_0)
print("NPU ready!")
print(f"Opening camera /dev/video{CAMERA_ID}...")
cap = cv2.VideoCapture(CAMERA_ID, cv2.CAP_V4L2)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
cap.set(cv2.CAP_PROP_FPS, 30)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print(f"Camera: {width}x{height}")
print("Detection running...\n")
fifo = open(FIFO_PATH, 'wb')
frame_count = 0
scale_x = width / IMG_SIZE
scale_y = height / IMG_SIZE
try:
while True:
ret, frame = cap.read()
if not ret:
time.sleep(0.1)
continue
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img_resized = cv2.resize(frame_rgb, (IMG_SIZE, IMG_SIZE))
img_input = np.expand_dims(img_resized, 0)
inf_start = time.time()
outputs = rknn_lite.inference(inputs=[img_input])
inf_time = (time.time() - inf_start) * 1000
input0 = outputs[0].reshape([3, -1] + list(outputs[0].shape[-2:]))
input1 = outputs[1].reshape([3, -1] + list(outputs[1].shape[-2:]))
input2 = outputs[2].reshape([3, -1] + list(outputs[2].shape[-2:]))
input_data = [
np.transpose(input0, (2, 3, 0, 1)),
np.transpose(input1, (2, 3, 0, 1)),
np.transpose(input2, (2, 3, 0, 1))
]
boxes, classes, scores = yolov5_post_process(input_data)
if boxes is not None:
self.draw_detections(frame, boxes, scores, classes, scale_x, scale_y)
obj_count = len(boxes)
else:
obj_count = 0
self.calc_fps()
cv2.rectangle(frame, (5, 5), (400, 120), (0, 100, 0), -1)
cv2.putText(frame, f'FPS: {self.fps:.1f}', (15, 35),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.putText(frame, f'NPU: {inf_time:.1f}ms', (15, 70),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.putText(frame, f'Objects: {obj_count}', (15, 105),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 0), 2)
_, jpeg = cv2.imencode('.jpg', frame, [cv2.IMWRITE_JPEG_QUALITY, 85])
fifo.write(jpeg.tobytes())
fifo.flush()
frame_count += 1
if frame_count % 50 == 0:
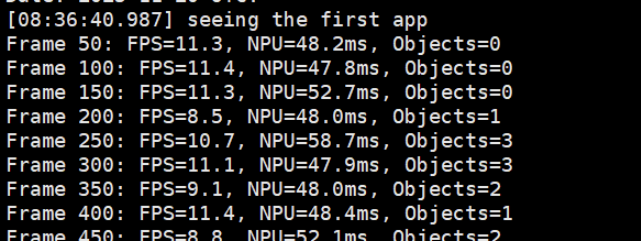
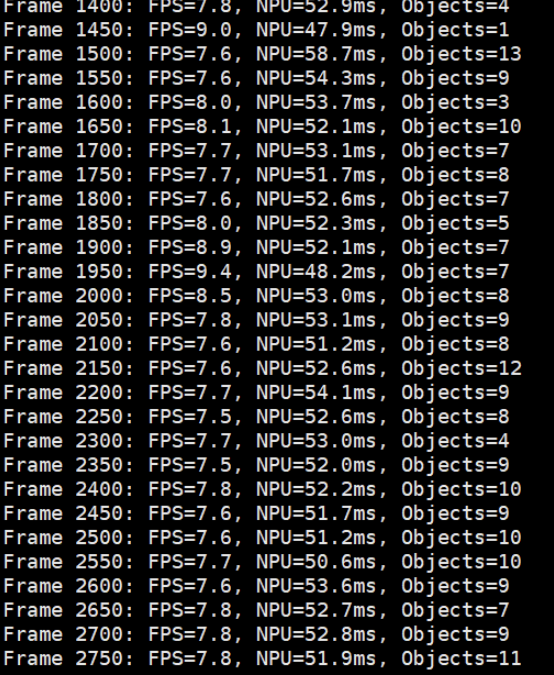
print(f"Frame {frame_count}: FPS={self.fps:.1f}, NPU={inf_time:.1f}ms, Objects={obj_count}")
except KeyboardInterrupt:
print("\nStopping...")
finally:
fifo.close()
cap.release()
rknn_lite.release()
print("Released resources")
YOLODetector().run()
PYTHON_CODE
PYTHON_PID=$!
echo ""
echo "=========================================="
echo "System started!"
echo "Screen should show real-time detection"
echo "Press Ctrl+C to exit"
echo "=========================================="
echo ""
trap "echo ''; echo 'Stopping...'; kill $PYTHON_PID $GST_PID 2>/dev/null; rm -f $FIFO_PATH; echo 'Cleaned up'; exit" INT
wait $PYTHON_PID
kill $GST_PID 2>/dev/null
rm -f $FIFO_PATH
echo "Cleaned"
EOF
chmod +x yolo_npu_display.sh